Оптимизация сетевого программного обеспечения для продвижения научных открытий
Команда компьютерных ученых физиков и разработчиков программного обеспечения оптимизировала программное обеспечение для высокоскоростной сети связи Intel для ускорения кодов приложений

Команда компьютерных ученых физиков и разработчиков программного обеспечения оптимизировала программное обеспечение для высокоскоростной сети связи Intel для ускорения кодов приложений для машинного обучения. Высокопроизводительные вычисления (HPC) - привелегия суперкомпьютеров и методов параллельной обработки для решения больших вычислительных задач - широко используются в научном сообществе.
Например, ученые из Брукхейвенской национальной лаборатории Министерства энергетики США полагаются на высокопроизводительные вычисления, чтобы проанализировать данные, которые они собирают на крупномасштабных экспериментальных установках на месте, и моделировать сложные процессы, которые было бы слишком дорого или невозможно продемонстрировать экспериментально.
Современные научные приложения, такие как моделирование взаимодействия частиц, часто требуют сочетания совокупной вычислительной мощности, высокоскоростных сетей для передачи данных, большого объема памяти и возможностей хранения большой емкости информации.
Достижения в области аппаратного и программного обеспечения HPC необходимы для удовлетворения этих требований. Ученые в области компьютерных и вычислительных технологий и математики из Инициативы по вычислительной науке (CSI) Брукхейвенской лаборатории сотрудничают с физиками, биологами и другими учеными в предметной области, чтобы понять их потребности в анализе данных и предоставить решения для ускорения процесса научных открытий.
Лидер отрасли HPC
В течение десятилетий корпорация Intel была одним из лидеров в разработке технологий высокопроизводительных вычислений. В 2016 году компания выпустила электронику , а именно процессоры Intel® Xeon Phi TM (ранее носившие кодовое название «Knights Landing») - архитектуру HPC второго поколения, которая объединяет множество процессорных блоков (ядер) на чип. В том же году Intel выпустила высокоскоростную сеть связи Intel® Omni-Path Architecture.
Чтобы 5000–100 000 отдельных компьютеров или узлов в современных суперкомпьютерах работали вместе для решения проблемы, они должны иметь возможность быстро обмениваться данными друг с другом, сводя к минимуму задержки в сети. Вскоре после этих выпусков Brook haven Lab и RIKEN, крупнейшее в Японии комплексное исследовательское учреждение, объединили свои ресурсы для покупки небольшого компьютера на 144 узла, построенного из процессоров Xeon Phi и двух независимых сетевых подключений с использованием архитектуры Omni-Path от Intel.
Компьютер был установлен в Научно-вычислительном центре Brook haven Lab, который является частью CSI. Завершив установку, физик Чулву Юнг и ученый CSI Мейфен Лин из Брукхейвенской лаборатории; физик-теоретик Кристоф Ленер, назначенец в Брукхейвенской лаборатории и Регенсбургском университете в Германии; Норман Крист, профессор вычислительной теоретической физики в Колумбийском университете им.
Эфраима Гилдора и физик-теоретик частиц Питер Бойл из Эдинбургского университета работал в тесном сотрудничестве с инженерами-программистами Intel над оптимизацией сетевого программного обеспечения для двух научных приложений: физики элементарных частиц и машинного обучения. «CSI очень интересовался архитектурой Intel Omni-Path с момента ее анонса в 2015 году», - сказал Лин.
«Опыт инженеров Intel имел решающее значение для реализации программных оптимизаций, которые позволили нам в полной мере использовать преимущества этой высокопроизводительной сети связи для наших конкретных потребностей приложений».
Требования к сети для научных приложений
Для многих научных приложений запуск одного ранга (значение, которое отличает один процесс от другого) или, возможно, нескольких рангов на узел на параллельном компьютере, намного эффективнее, чем запуск нескольких рангов на узел. Каждый ранг обычно выполняется как независимый процесс, который связывается с другими рангами с использованием стандартного протокола, известного как Интерфейс передачи сообщений (MPI).
Например, физики, стремящиеся понять, как образовалась вселенная, проводят сложные численные моделирования взаимодействий частиц на основе теории квантовой хромодинамики (КХД). Эта теория объясняет, как элементарные частицы, называемые кварками и глюонами, взаимодействуют с образованием частиц, которые мы непосредственно наблюдаем, таких как протоны и нейтроны.
Физики моделируют эти взаимодействия, используя суперкомпьютеры, которые представляют три измерения пространства и измерение времени в четырехмерной (4D) решетке с одинаково расположенными точками, подобными кристаллу.
Решетка разбита на меньшие идентичные подобъемы. Для расчетов КХД с решеткой необходимо обмениваться данными на границах между различными подобъемами. Если существует несколько рангов на узел, каждый ранг размещает свой отдельный 4-мерный том. Таким образом, разделение вложенных томов создает больше границ, где необходимо обмениваться данными, и, следовательно, ненужные передачи данных, которые замедляют вычисления.
Оптимизация программного обеспечения для развития науки
Чтобы оптимизировать сетевое программное обеспечение для такого сложного в вычислительном отношении научного приложения, команда сосредоточилась на повышении скорости одного ранга. «Мы сделали код для одного ранга MPI более быстрым, чтобы не требовалось увеличение рангов MPI для обработки большой коммуникационной нагрузки для каждого узла», - пояснил Христиан. Программное обеспечение в ранге MPI использует многопоточный параллелизм, доступный на узлах Xeon Phi.
Поточный параллелизм относится к одновременному выполнению нескольких процессов или потоков, которые следуют одним и тем же инструкциям при совместном использовании некоторых вычислительных ресурсов. Благодаря оптимизированному программному обеспечению команда смогла создать несколько каналов связи на одном уровне и управлять этими каналами, используя разные потоки.
Программное обеспечение MPI теперь было настроено для более быстрого запуска научных приложений и использования всех преимуществ коммуникационного оборудования Intel Omni-Path. Но после внедрения программного обеспечения члены команды столкнулись с другой проблемой: при каждом запуске несколько узлов неизбежно связывались бы медленно и сдерживали другие. Они проследили эту проблему до способа, которым Linux - операционная система, используемая большинством платформ HPC - управляет памятью.
В режиме по умолчанию Linux делит память на небольшие куски, называемые страницами. Переконфигурировав Linux для использования больших («огромных») страниц памяти, они решили проблему. Увеличение размера страницы означает, что для сопоставления виртуального адресного пространства, используемого приложением, требуется меньше страниц. В результате к памяти можно получить доступ намного быстрее.
Благодаря усовершенствованиям программного обеспечения члены группы проанализировали производительность процессорных вычислительных узлов Intel Omni-Path и процессоров Intel Xeon Phi, установленных на двухжелентном кластере Intel «Diamond» и однолинейном кластере распределенных исследований с использованием современных вычислений (DiRAC). Соединенное Королевство. Для их анализа они использовали два разных класса научных приложений - физика элементарных частиц и машинное обучение.
Для обоих прикладных кодов они достигли скорости, близкой к скорости передачи - теоретической максимальной скорости передачи данных. Это улучшение представляет собой увеличение производительности сети в четыре-десять раз по сравнению с исходными кодами. «Благодаря тесному сотрудничеству между Брукхейвеном, Эдинбургом и Intel, эти оптимизации стали доступны во всем мире в новой версии реализации Intel Omni-Path MPI и протоколе наилучшей практики для настройки управления памятью в Linux», - сказал Христос.
«Фактор пятикратного ускорения выполнения физического кода на компьютере Xeon Phi в Brook haven Lab - и на новом, еще более крупном 800-узловом компьютере« гиперкуба »Hewlett Packard Enterprise с 800 узлами - теперь находит хорошее применение.в текущих исследованиях фундаментальных вопросов физики элементарных частиц ".
Автор статьи: Виктор Булавин
Похожие статьи:

 Может сделать практически любую поверхность сенсорной новая технология ультразвука
Может сделать практически любую поверхность сенсорной новая технология ультразвука
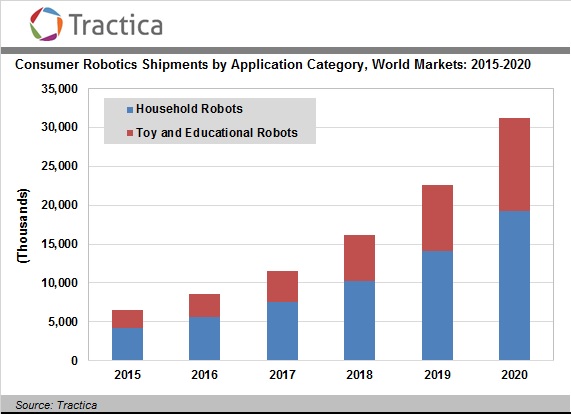 100 млн. бытовых роботов будут проданы за следующие 5 лет
100 млн. бытовых роботов будут проданы за следующие 5 лет

 38% рабочих мест в США могут быть быстро захвачены роботами
38% рабочих мест в США могут быть быстро захвачены роботами

 В живую лабораторию превращают мост датчики
В живую лабораторию превращают мост датчики

 Облегчают создание современных материалов и специализированного программного обеспечения роботы
Облегчают создание современных материалов и специализированного программного обеспечения роботы

 Для улучшения благосостояния студентов этот робот использует методы позитивной психологии
Для улучшения благосостояния студентов этот робот использует методы позитивной психологии







