Оживляет Мона Лизу или любую другую картинку Samsung AI
Используя новейшую тенденцию в области искусственного интеллекта - состязательное обучение - центр ИИ Samsung в Москве продемонстрировал, что он может сделать с одним изображение человека

Используя новейшую тенденцию в области искусственного интеллекта - состязательное обучение - центр искусственного интеллекта Samsung в Москве продемонстрировал, что он может сделать одно изображение человека и анимировать его голову.
И если наблюдение за тем, как Мона Лиза оживает, не вызывает озноб по спине, вам нужно проверить свой пульс. Система берет несколько изображений человека –количество картинок изменяется для лучших результатов - и исследует его через специальное ПО, чтобы определить, где глаза, брови, нос губы и челюсть. То же самое относится и к другому «движущемуся» исходному видео, проходя кадр за кадром, чтобы отслеживать движение этих ориентиров лица.
Составляющие системы
Существует отдельная стадия метаобучения, на которой различные сети искусственного интеллекта обучаются выполнять различные задания с использованием огромного набора видеоданных говорящих голов. Сеть Embedder использует исходные кадры и данные отслеживания их ориентиров для создания векторов, в то время как сеть Generator учится использовать векторы и изображения и генерировать короткие видеоролики, в которых неподвижные лица анимированы для перемещения в соответствии с векторным движением.

Третья сеть «Дискриминатор» устанавливает состязательные отношения - она учится смотреть видео с движущимися лицами и говорить, какие из них являются настоящими, а какие были сфальсифицированы сетью Генераторов. Итак, у вас есть две сети, работающие друг против друга - одна пытается обмануть другую, другая пытается обнаружить подделки.
Развитие сетей
Эти сети пока очень плохо выполняют свою работу, но, выполняя свою работу миллионы раз, они начинают улучшаться, и конкуренция между двумя сетями является движущей силой обеих компаний. Сеть Discriminator не ищет того, что ищет другая, но это не имеет значения - что бы оно ни искало, оно становится все лучше в распознавании, поэтому сеть генератора должна постоянно улучшаться, продолжая дурачить другую.

Это еще один проблеск очень захватывающего потенциала Генеративных Состязательных Сетей, которые появляются во всем мире ИИ. Но чтобы по-настоящему оценить это, вам нужно посмотреть видео ниже. Перейдите на 4:16 минуту, если вы хотите сразу увидеть, как модель демонстрирует одиночные кадры с Мэрилин Монро, Сальвадора Дали, Распутина и Эйнштейна, а затем переходит к живописи.

Просматривая три разных видео с одним водителем, на каждом лице изображены три совершенно разные личности - это просто намек на то, насколько актер может изменить свою воспринимаемую личность, научившись использовать мышцы лица и тела по-разному. И увидев, как Мона Лиза оживает, может вызвать у вас улыбку - пока вы не подумаете, что такое развитие событий означает для еще более реалистичного и легкого создания глубоких подделок.
Автор статьи: Виктор Булавин
Похожие статьи:

 Лаборатория для изучения взаимодействия человека и робота
Лаборатория для изучения взаимодействия человека и робота

 Для улучшения балансировки роботов ученые создали роботизированный хвост Arque
Для улучшения балансировки роботов ученые создали роботизированный хвост Arque

 Пчелы и рыбы учатся общаться на большом расстоянии - с помощью роботов
Пчелы и рыбы учатся общаться на большом расстоянии - с помощью роботов

 Посадить корабль на Луну в 2022 году хотят в компании SpaceX
Посадить корабль на Луну в 2022 году хотят в компании SpaceX
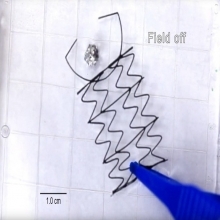
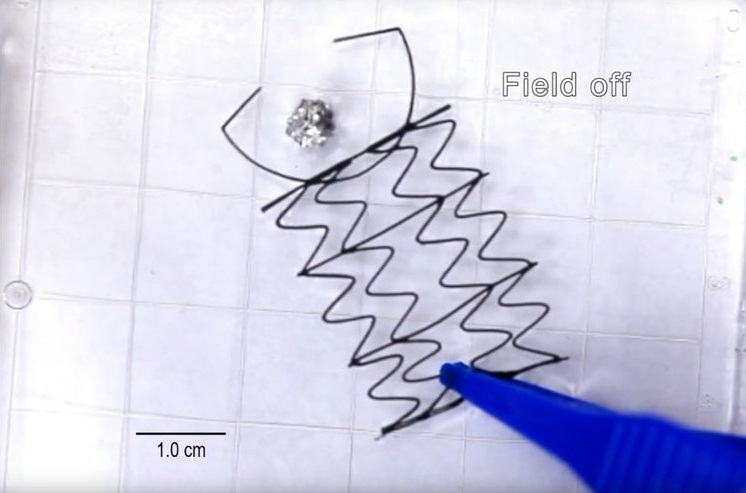 3D-печатные роботы плавают сгибаются и захватывают предметы по команде
3D-печатные роботы плавают сгибаются и захватывают предметы по команде

 Вдохновляет на новые идеи для машинного обучения биологическая эволюция
Вдохновляет на новые идеи для машинного обучения биологическая эволюция







